Multithreading Visualization: C vs Python
I wanted to see how threads actually behave on a real machine, not just in theory.
So I spun up an EC2 instance and ran both CPU-bound and I/O-mixed workloads in C and Python, with two variations:
- Threads pinned to specific CPUs
- Threads unpinned, letting the Linux scheduler decide
I used perf and timechart to visualize thread activity. Here’s what I found.
Note: The code used is available here and here.
1. The four experiments
C workload, CPU pinned

- Threads stayed fixed to their assigned cores.
- Execution blocks were long and continuous, showing minimal migration.
- Very predictable and efficient, but if some threads finished early, a few cores went underutilized.
Python workload, CPU pinned

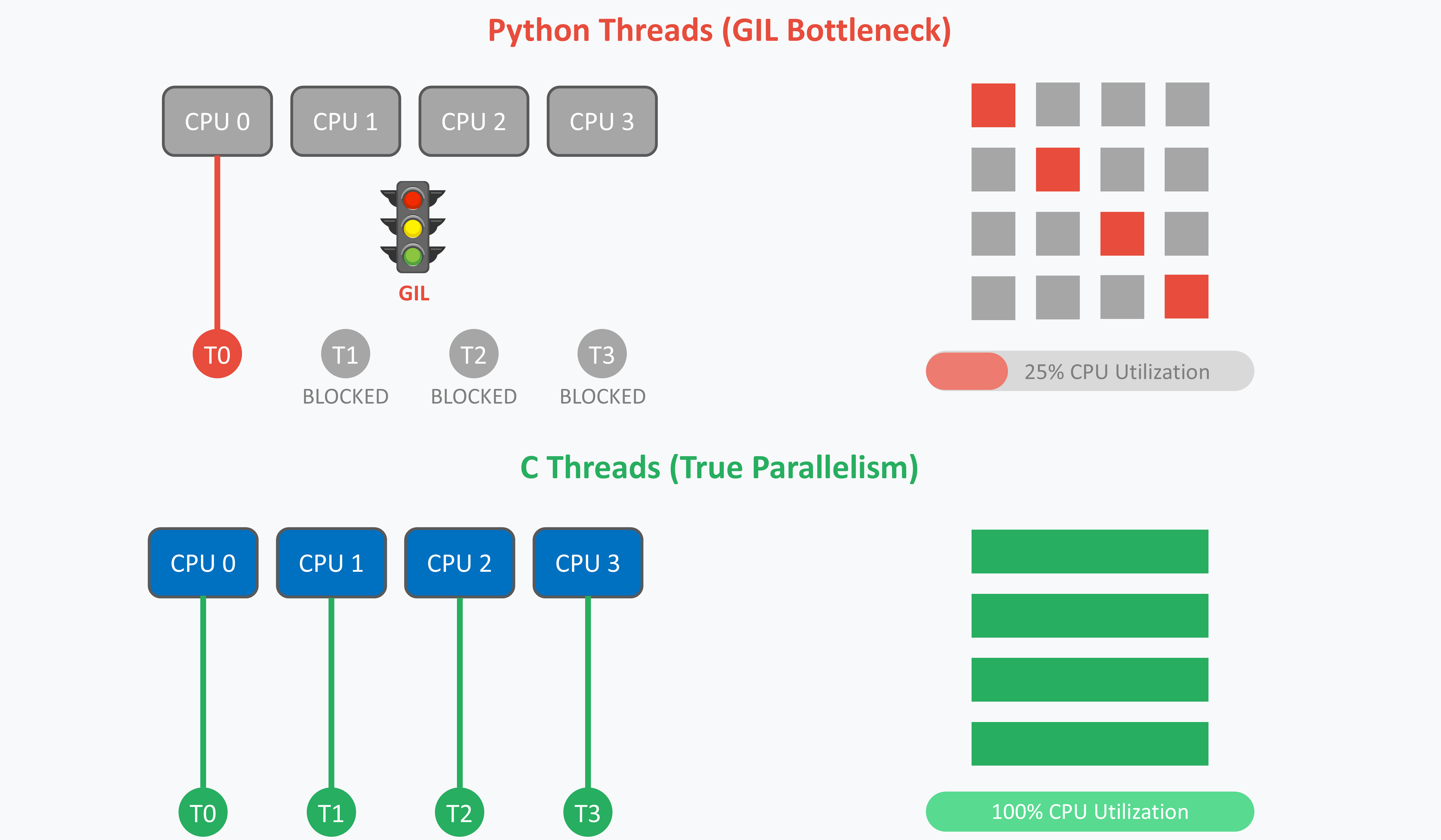
- Even with threads pinned, only one was truly active at a time.
- Other threads waited because of the Global Interpreter Lock (GIL).
- The chart looks sparse: lots of idle gaps.
C workload, unpinned

- Threads migrated between cores as the Linux scheduler balanced load.
- More context switches, but overall CPU utilization was still high.
- Linux did a good job keeping all cores busy.
Python workload, unpinned

- Same story as pinned: the GIL kept CPU-bound execution serial.
- Threads migrated between cores, but only one was active at a time.
- Unpinning gave no real improvement.
2. Why Python has a GIL
Python’s Global Interpreter Lock is a mutex that prevents multiple native threads from executing Python bytecode at the same time.
Why does it exist?
- Memory safety: CPython’s memory management (reference counting) isn’t thread-safe. The GIL keeps it simple.
- Simplicity: Removing the GIL would require pervasive locking or atomic operations throughout the interpreter, hurting single-thread performance.
- Practicality: Many Python workloads are I/O-bound (network, disk). The GIL doesn’t block I/O concurrency, so for those use cases it’s “good enough.”
The tradeoff: Python threads are fine for I/O concurrency, but they don’t give you CPU parallelism.
3. Cache locality and pinning
In C:
- Pinning a thread to a CPU core improves cache locality.
- The data a thread frequently uses stays in that core’s L1/L2 caches.
- This reduces cache misses, making execution faster and more deterministic.
- Downside: if a pinned thread finishes early, that core may sit idle while others are still overloaded.
In Python:
- Even when only one thread runs at a time (due to the GIL), cache locality still matters for per-thread latency and determinism, and it becomes crucial when threads execute native C code or perform blocking I/O that releases the GIL.
- Threads may migrate, but since there’s no true parallelism in CPU-bound code, the benefits of pinning don’t materialize.
4. Key takeaways
- C + pinned: Best for determinism and cache affinity.
- C + unpinned: Slightly noisier, but Linux balances well — all cores stay busy.
- Python (pinned or not): Same bottleneck — the GIL. No true parallelism for CPU-bound tasks.
- I/O workloads: Python threads are still useful for overlapping I/O waits, since the GIL is released during blocking I/O.
5. Lessons
- If you need CPU-bound parallelism in Python → use multiprocessing, or drop into C/C++/Rust extensions (NumPy, Cython, etc.).
- For I/O concurrency, Python threads are fine.
- If you want to see the difference, perf timecharts make the contrast obvious:
- C = full utilization, parallel blocks across cores
- Python = serialized execution, idle gaps
6. When this actually matters
Understanding threading behavior isn’t just academic—it directly impacts real applications:
Image/video processing: Libraries like OpenCV use C extensions under the hood. When you call cv2.resize() or apply filters, you’re getting true parallelism despite running from Python. Pure Python image manipulation would crawl.
Scientific computing: NumPy and SciPy operations release the GIL and use optimized C/Fortran code. Matrix multiplication with numpy.dot() can use all your cores, but a pure Python nested loop cannot.
Web servers: Frameworks like FastAPI and asyncio work well despite the GIL because web apps are I/O-bound. The GIL is released during database queries, file reads, and network requests. Threads spend most of their time waiting, not computing.
Machine learning: Training loops in pure Python would be painfully slow. Libraries like PyTorch and TensorFlow drop into C++/CUDA for the heavy lifting, only using Python for orchestration.
The pattern is clear: Python excels at coordination and glue code, while performance-critical work gets delegated to compiled extensions.
7. A kitchen metaphor
Think of CPU cores as kitchen stations, and threads as chefs:
C threads: Four chefs, each with their own fully-equipped station. Everyone cooks simultaneously—onions sizzling, pasta boiling, sauces reducing. Pure parallel efficiency.
Python threads: Four chefs, but only one knife in the entire kitchen. No matter how many stations you have, only one chef can work at a time. The others stand around waiting for their turn with the knife.
The GIL is that single shared knife - a bottleneck that forces serialization no matter how much kitchen space (CPU cores) you have available.
In short:
C threads light up your CPUs like a busy restaurant kitchen.
Python threads, for CPU-bound work, just pass the knife around.